Beyond Simulation: The Strategic Imperative of Adversarial Exposure Validation (AEV)
December 2, 2025
The 2026 Data Loss Prevention (DLP) Essential List: 10 Must-Have Elements for the Public Sector
December 23, 2025Architecting Data for the AI Era
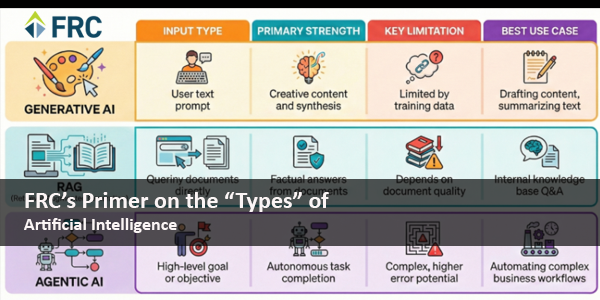
Enterprise storage has historically been architected for capacity, not cognition. We often optimized for ‘write-once, read-not-that-often’ data lakes that prioritized cost per gigabyte over time-to-inference.
However, the rise of Generative AI – that relies on context provided by Retrieval-Augmented Generation (RAG) — and autonomous AI agents has inverted these requirements. In an AI-driven architecture, data is no longer a static artifact; it is the active context required for reasoning. If your infrastructure treats data as a passive archive, your AI models will suffer from hallucinations, latency, and a lack of grounding. To transition from experimental chatbots to mission-critical agents, we must re-engineer the storage layer to function less like a warehouse and more like an extension of the model’s own memory—instant, indexed, and actionable.
To prepare your infrastructure for AI, you must evolve your thinking of storage as a warehouse and start treating it as the “synaptic memory” of your organization. Here is a breakdown of how to rethink data residency and accessibility to support the next generation of intelligent applications.
1. The “Where”: Solving for Data Gravity and Residency
The first challenge is physics. Data has “gravity”. That is, as datasets grow, they become harder to move, forcing applications and compute to orbit around them. In the legacy model, we moved data to the compute. Today, we must bring the compute (and the AI models) to the data.
However, not all data requires the same access speed. To make data “timely” for an AI agent without bankrupting your infrastructure, you need a Tiered Architecture. AI agents function like human analysts: they need immediate access to current events, but can afford to wait slightly longer for historical context.
- Hot Tier (Milliseconds): High-performance SSDs/NVMe. This is where your active threat logs, current user session data, and “live” indices reside. Agents access this tier for real-time inference and decision-making.
- Warm Tier (Seconds): Standard performance storage for recent history (e.g., last month’s incident reports).
- Cold/Frozen Tier (Minutes/Hours): Object storage (S3/Blob) for deep archival and compliance logging.

The critical success factor here is transparency. AI agent shouldn’t need to know where the data is, it should just know what it needs. This is where platforms like Elastic distinguish themselves. Through Index Lifecycle Management (ILM), data automatically migrates between these tiers based on policy (e.g., age, size, or priority). The agent simply queries the cluster, and the system retrieves the answer, seamlessly spanning from hot RAM to cold object storage without breaking the search context.
2. The “How”: Vectors and the Language of AI
Storing data is the easy part; understanding it is the hard part. Traditional databases rely on keyword matches. If you search for “unauthorized admin access,” a standard database might miss a critical log entry that says “root escalation detected” because the keywords do not match exactly.
To make data accessible to AI, it must be transformed into Vectors.
Vectorization converts unstructured text, images, or logs into long lists of numbers (embeddings) that represent meaning rather than just syntax. These numbers are plotted as coordinates in a multi-dimensional space. Concepts that are similar—like “login failed” and “bad password”—are stored close together in this mathematical space.
By utilizing a Vector Database, your AI agents can perform semantic search. They don’t just look for words; they look for intent. If your data isn’t vectorized, your AI is effectively blind to the context hidden within your logs.
3. The “Action”: Hybrid Search and RAG
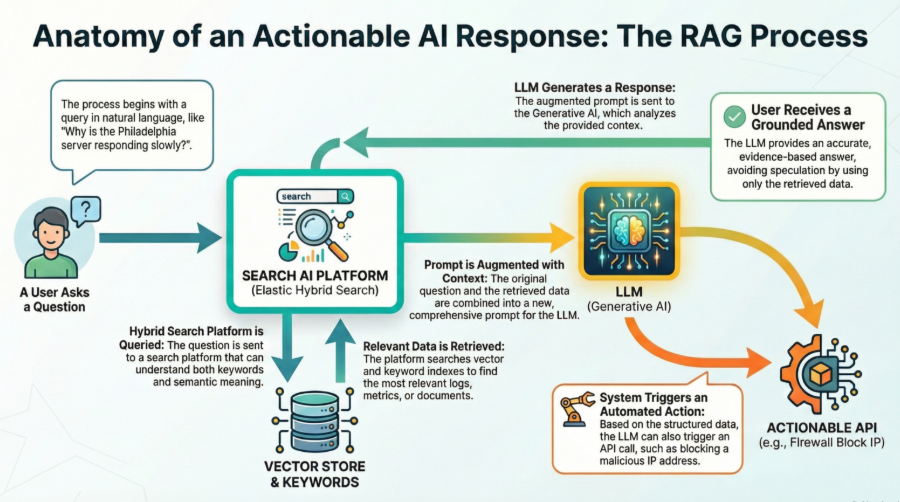
We want our AI to read data and act on it. This requires a pattern known as Retrieval-Augmented Generation (RAG).
When a user asks, “Why is the Philadelphia server responding slowly?”, the system follows a specific flow:
- Retrieval: The system searches the database for relevant logs and metrics.
- Generation: The LLM reads those specific logs to generate a diagnosis.
But for this to work in a mission-critical environment, pure vector search is often insufficient. Vectors are great for concepts (“Show me scary things”), but they can be fuzzy on specifics (“Show me IP address 10.10.5.1”).
This is why we leverage Elastic’s Search AI Platform. Unlike standalone vector databases that only understand embeddings, Elastic performs Hybrid Search. It runs a vector search (for concept) and a traditional keyword search (for precision) simultaneously.
Furthermore, with tools like ELSER (Elastic Learned Sparse EncodeR), organizations can implement this semantic retrieval without needing to train and manage complex machine learning models in-house. It allows for semantic search out-of-the-box, providing an “easy button” for relevance, ensuring the AI agent retrieves the right data to take the right action.
4. Real-World Scenario: The Automated SOC Analyst
To visualize this, imagine a Security Operations Center (SOC).
- The Trigger: A user reports “weird email activity.”
- The Search: The AI agent queries the Elastic datastore using Hybrid Search.
- Vector Component: Looks for emails semantically similar to known phishing templates.
- Keyword Component: Filters specifically for the user’s email address and the timeframe.
- The Action: The search returns a specific JSON object containing the malicious email headers. Because the data is structured, the AI agent can parse the “Sender IP” field and automatically utilize a predefined tool or function to trigger a firewall API blocking that IP..
This transition—from unstructured complaint to structured API action—is only possible because the data was stored in a way that supported both semantic understanding and structured retrieval.
5. Security and Residency: The Air-Gapped Advantage
Finally, accessibility cannot come at the cost of security. For sectors dealing with sensitive information (specifically the Department of Defense (DoD) and Federal Government) shipping data to a public cloud model to be indexed is a non-starter.
The architecture described above supports running your models and accessing your data locally. By running the Vector Database and hosting the LLM on-premise or in an air-gapped environment, you ensure that while the AI “reads” the data to form an answer, the source of truth never leaves your secure perimeter.
You do not need to expose your classified or CUI (Controlled Unclassified Information) data to the internet to leverage GenAI. By bringing the search platform inside the wire, you maintain data sovereignty while still empowering your teams with modern AI capabilities.
Conclusion
To build AI that works, we must abandon the “data swamp” mentality. Your storage layer is now your inference engine.
By utilizing tiered storage to manage costs, vector embeddings to capture meaning, and hybrid search to ensure precision, we transform raw data into a responsive, actionable knowledge base. This is the foundation required to move beyond simple chatbots and towards true, autonomous AI agents that can defend, analyze, and act on your behalf.