
How Trellix Mobile Security Enables Compliance with DISA STIG Mandates for Mobile Security with Android 16 and iOS 26
February 12, 2026
Understanding OPORD 8600-25: What DoD Organizations Must Know
March 3, 2026What Public Sector Agencies Need to Know about Vector Databases and Creating LLM-powered Applications
Public sector agencies are currently facing a significant opportunity to improve how they serve citizens, accelerate decision-making, and better achieve their mission. Large Language Models (LLMs) offer a way to interact with information using natural language. However, for a government agency, an LLM alone is not enough. To be useful, it needs access to specific, private, and up-to-date agency data without “hallucinating” or making up facts.
The solution is a Vector Database. Vector databases can act as a specialized memory for AI, allowing it to find and use the right information at the right time. They allow your LLMs access to your agency’s pertinent information and establish the truth within the organization. Without internal knowledge or a baseline of truth, your LLM applications will likely not be successful.
Understanding the Basics: What is a Vector?
To understand a vector database, we first need to understand vectors. Traditional databases store information in tables with rows and columns, searching for exact matches of words. A vector database stores data as numerical representations called embeddings. Think of a vector as a set of mathematical coordinates. In a simple 2D map, a point is defined by two numbers (latitude and longitude). In a vector database, a piece of text (like a policy document or an email) is turned into a list of hundreds or even thousands of numbers. These numbers represent the meaning of the content.
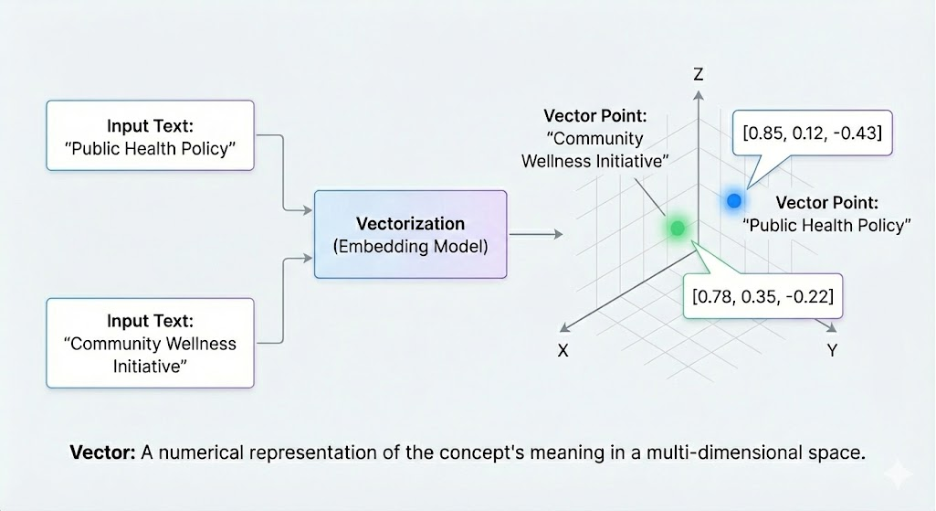
Because these “coordinates” represent meaning, the database can perform a similarity search. If two documents are about similar topics—for example, “voter registration” and “ballot applications”—their numerical vectors will be mathematically “close” to each other, even if they don’t share the exact same words. This allows the system to find relevant information based on the intent of a user’s question, rather than just matching keywords.
Traditional databases are like a library catalog where you search by the exact title or author. A vector database is like a librarian who understands the meaning of your question. If you ask for ‘books about the Cold War,’ a traditional search might miss a book titled ‘The Iron Curtain.’ A vector database knows they are related concepts and finds it anyway.
How Vector Databases Enable the Use of AI
Vector databases serve as the “long-term memory” for LLMs. While LLMs are highly skilled at reasoning, they do not have a built-in memory of an agency’s private or real-time data after their initial training is complete.
- Bridging the Context Gap: They provide a context layer between an agency’s private data and the LLM, ensuring the AI uses mission-specific facts to “ground” its response.
- Processing Unstructured Data: Roughly 80% of data is unstructured, such as PDFs, audio, and video. Vectors turn this disparate data into searchable numerical formats.
- Semantic Intent: Vectors allow the system to understand that a query for “public records” is related to “FOIA requests,” even if the words differ.
- High-Performance Retrieval: Specialized algorithms allow the database to search millions of records in milliseconds, providing the scalability required by major government departments.
The RAG Framework: Giving AI a “Ground Truth”
For government agencies, accuracy is non-negotiable. To control errors, agencies use a framework called Retrieval-Augmented Generation (RAG).
RAG works by adding a “context layer” between your agency’s private data and the LLM. Here is how the process works:
- The Question: A user asks a question, such as “What are the requirements for a small business grant?”.
- The Retrieval: The system turns that question into a vector and searches the Vector Database to find the most relevant document “chunks”.
- The Context Window: Instead of asking the AI to answer from its general memory, the system gives the AI the specific document chunks it just found.
- The Answer: The AI reads the provided documents and generates a response based only on those facts.
This process ensures that answers are accurate, relevant, and actionable. It also provides a clear “paper trail,” as the system can cite exactly which document it used.
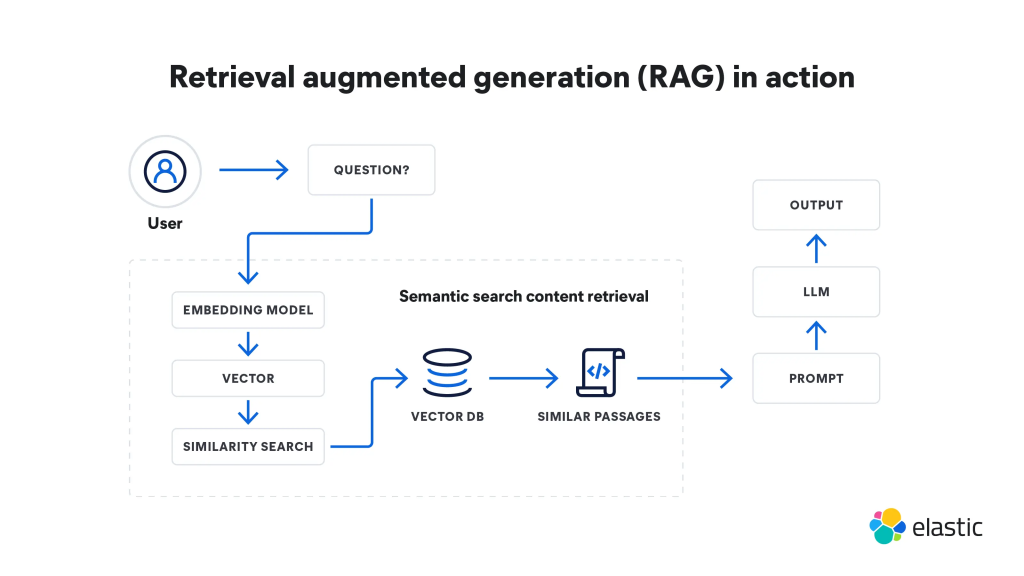
(What is Retrieval Augmented Generation (RAG)? | A Comprehensive RAG Guide | Elastic)
How Elastic Supports Public Sector AI

Elastic provides a unified platform that addresses the specific technical and security requirements of government work.
1. Hybrid Search: Combining Keywords and Meaning
Pure vector search can struggle with exact identifiers like case numbers. Elastic uses Hybrid Search, combining traditional keyword matching (BM25) with semantic vector search to ensure users find exactly what they need.
2. Multi-Modal Capabilities
Public sector data includes PDFs with complex tables and video footage. Elastic supports multi-modal search, allowing agencies to search across text, images, and audio simultaneously to find information hidden deep within files, such as a specific diagram or a phrase mentioned in a video.
3. Security and Access Control
Security is paramount. Elastic integrates Role-Based Access Control (RBAC) directly into the search process. This ensures the AI only retrieves and uses documents that the specific user is authorized to see.
4. Deployment in Air-Gapped Environments
Defense and intelligence agencies often operate in air-gapped environments. Elastic is the first vector database to offer a fully supported air-gapped option for advanced features like semantic reranking.
Performance and Efficiency
Deploying AI at scale must be cost-effective and fast.
- Query Speed: Elastic provides up to 12x faster query speeds than some other vector databases like OpenSearch.
- Accuracy: Agencies can see a 30% uplift in search accuracy.
- Vector Compression: Techniques like Better Binary Quantization (BBQ) compress vectors, making them faster to search and requiring less storage.
Conclusion
The transition from traditional search to LLM-powered applications requires a fundamental shift in data strategy. To review the core requirements for public sector adoption:
- Groundedness: Systems must prioritize RAG to ensure mission-critical answers are accurate and free from hallucinations.
- Security: Privacy-first AI must respect existing security protocols (RBAC/ABAC) and data sovereignty.
- Flexibility: Solutions must support diverse data types (multi-modal) and diverse environments (cloud to air-gapped).
Vector databases are the fundamental technology that allows public sector agencies to turn vast archives into a functional knowledge base for AI. By using a platform like Elastic, agencies can ensure their applications are secure, accurate, and capable of running in any environment.
Contact us to schedule a demo on Elastic or discuss more about vector databases and building AI-powered solutions.


